6. Probability and Statistics#
One way or another, machine learning is all about uncertainty. In supervised learning, we want to predict something unknown (the target) given something known (the features). Depending on our objective, we might attempt to predict the most likely value of the target. Or we might predict the value with the smallest expected distance from the target. And sometimes we wish not only to predict a specific value but to quantify our uncertainty. For example, given some features describing a patient, we might want to know how likely they are to suffer a heart attack in the next year. In unsupervised learning, we often care about uncertainty. To determine whether a set of measurements are anomalous, it helps to know how likely one is to observe values in a population of interest. Moreover, in reinforcement learning, we wish to develop agents that act intelligently in various environments. This requires reasoning about how an environment might be expected to change and what rewards one might expect to encounter in response to each of the available actions.
Probability is the mathematical field concerned with reasoning under uncertainty. Given a probabilistic model of some process, we can reason about the likelihood of various events. The use of probabilities to describe the frequencies of repeatable events (like coin tosses) is fairly uncontroversial. In fact, frequentist scholars adhere to an interpretation of probability that applies only to such repeatable events. By contrast Bayesian scholars use the language of probability more broadly to formalize our reasoning under uncertainty. Bayesian probability is characterized by two unique features: (i) assigning degrees of belief to non-repeatable events, e.g., what is the probability that the moon is made out of cheese?; and (ii) subjectivity—while Bayesian probability provides unambiguous rules for how one should update their beliefs in light of new evidence, it allows for different individuals to start off with different prior beliefs. Statistics helps us to reason backwards, starting off with collection and organization of data and backing out to what inferences we might draw about the process that generated the data. Whenever we analyze a dataset, hunting for patterns that we hope might characterize a broader population, we are employing statistical thinking. Most courses, majors, theses, careers, departments, companies, and institutions have been devoted to the study of probability and statistics. While this section only scratches the surface, we will provide the foundation that you need to begin building models.
6.1. A Simple Example: Tossing Coins#
We can get out 0 and 1 with probability 0.5 each by testing whether the returned float is greater than 0.5
num_tosses = 100
heads = sum([rand() > 0.5 for _ in 1:100])
tails = num_tosses - heads
print("heads:$(heads), tails:$(tails) ")
heads:52, tails:48
More generally, we can simulate multiple draws from any variable with a finite number of possible outcomes (like the toss of a coin or roll of a die) by calling the Binomial type from Distributions.jl, setting the first argument n to the number of draws and the second p as probability of success in an individual trial (omit for p=0.5). To simulate ten tosses of a fair coin, we omit second argument p. The function rand returns a random element or array of random elements from the set of values, where tells us the number of occurrences of heads.
using Distributions
heads = rand(Binomial(num_tosses))
tails = num_tosses - heads
heads,tails
(55, 45)
Each time you run this sampling process, you will receive a new random value that may differ from the previous outcome. Dividing by the number of tosses gives us the frequency of each outcome in our data. Note that these frequencies, like the probabilities that they are intended to estimate, sum to 1.
(heads,tails)./num_tosses
(0.55, 0.45)
Here, even though our simulated coin is fair, the counts of heads and tails may not be identical. That is because we only drew a finite number of samples. If we did not implement the simulation ourselves, and only saw the outcome, how would we know if the coin were slightly unfair or if the possible deviation from 1/2 was just an artifact of the small sample size? Let’s see what happens when we simulate 10000 tosses.
num_tosses = 10000
heads = rand(Binomial(num_tosses))
tails = num_tosses - heads
(heads,tails)./num_tosses
(0.5111, 0.4889)
Let’s get some more intuition by studying how our estimate evolves as we grow the number of tosses from 1 to 10000.
using CairoMakie
counts = rand(Binomial(1),num_tosses)
cum_counts = cumsum(counts)
estimates = cum_counts ./ collect(1:num_tosses)
x = 1:num_tosses
fg,ax = lines(x, estimates ,label="P(coin=heads)";
axis=(;yticks = 0.0:0.2:1.0,xticks = 0:2000:num_tosses,xlabel = "Samples",ylabel = "Estimated probability"))
lines!(x, ones(num_tosses).-estimates, label="P(coin=tails)")
axislegend()
hlines!(ax,0.5,color=:black,linestyle=:dash)
fg
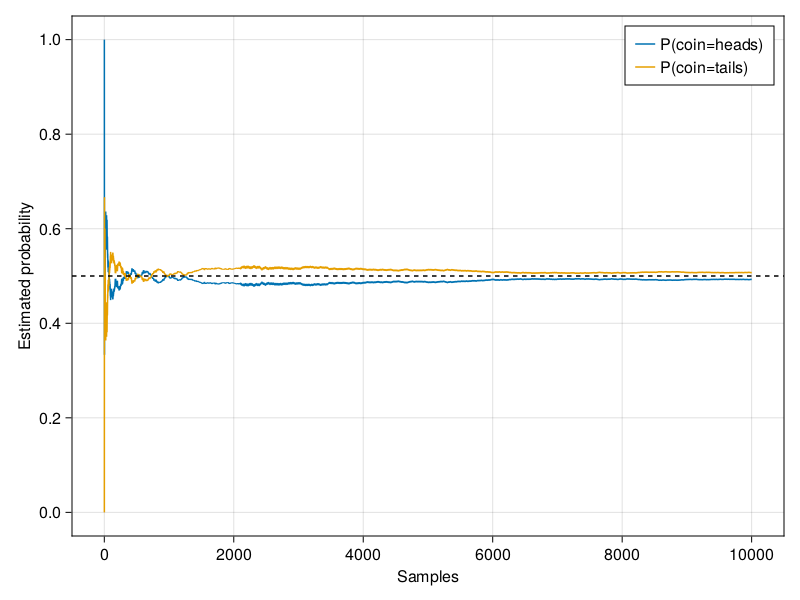
Each solid curve corresponds to one of the two values of the coin and gives our estimated probability that the coin turns up that value after each group of experiments. The dashed black line gives the true underlying probability. As we get more data by conducting more experiments, the curves converge towards the true probability.